|
|
Character set up to date to Unicode 12.
The tool as a whole is a new version, public in early stages. As I work on it, it will be missing features, occasionally its data, and sometimes give errors.
Input currently recognised:
- String with any characters, e.g. ㋛ ☺ ㋡ or € or (ノಠ益ಠ)ノ彡┻━┻ or ᘛ⁐̤ᕐᐷ or ༼ つ ◕_◕ ༽つ or ♥︎ ♥️ or ◡̈.
- Refereces to one or more codepoints (one style at a time)
- U+205AC, U+1F9C0, U+2764
- 0420, c3a9, e2808b - hex that is codepoint and/or UTF8 (e.g. e2808b is probably U+200B, c3a9 could be either U+E9 or U+C3A9)
- %C3%A9 - percent-encoded hex UTF8 (probably from URLs)
- \xd0\xa0, \uc3a9, \u{c3a9}, \ud83e\uddc0, \U0001F9C0 - some escape styles used in code
- ➨, ➨, · decimal/hex/named HTML/XML entity
- Name search such as cyrillic de, n, numeral, plus-minus sign, exclamation question, arrow right, hieroglyph. Includes entity names like middot and Ntilde, and some of my own fuzziness, also to help find confusables.
Or you could get a random character.
|
| Type here |
|
| Input was | U+250D |
|---|
| Interpretation | Assuming this is a U+ style codepoint for U+250D
Looks like a single character, or reference to one. Will describe as such. |
|---|
|
|---|
|
| Name search | no interesting words to search for |
|---|
|
|---|
|
| Character | ┍U+250D |
|---|
Character
image | 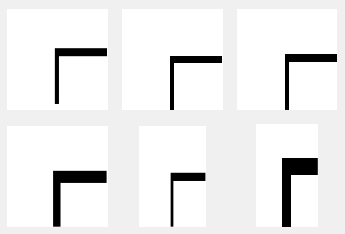 |
|---|
| Nearby characters |
⓵
⓶
⓷
⓸
⓹
⓺
⓻
⓼
⓽
⓾
⓿
─
━
│
┃
┄
┅
┆
┇
┈
┉
┊
┋
┌
┍
┎
┏
┐
┑
┒
┓
└
┕
┖
┗
┘
┙
┚
┛
├
┝
┞
┟
┠
┡
┢
┣
┤ |
|---|
Confusables
(experiment, needs work) |
|
|---|
|
|---|
|
| Character name | BOX DRAWINGS DOWN LIGHT AND RIGHT HEAVY |
|---|
| Categories | other symbol, Other Neutrals |
|---|
| Links elsewhere | codepoints.net · fontspace · fileformat.info |
|---|
| In block | Box Drawing, U+2500 to U+257F (PDF on unicode.org) |
|---|
In unicode since approx
| 1995 |
|---|
|
|---|
|
|
|---|
|
| Normalization | No normalisations change the data
(does not necessarily mean nothing decomposes to this form) |
|---|
| Encodings that can encode this properly | utf_8 utf_16 utf_32 iso2022_jp_2 iso2022_kr gb2312 gbk gb18030 euc_kr hz johab cp949 |
|---|
| Encodings that will mangle your text | ascii latin_1 iso8859_2 iso8859_3 iso8859_4 iso8859_5 iso8859_6 iso8859_7 iso8859_8 iso8859_9 iso8859_10 iso8859_13 iso8859_14 iso8859_15 iso2022_jp iso2022_jp_1 iso2022_jp_2004 iso2022_jp_3 iso2022_jp_ext big5 big5hkscs euc_jp euc_jis_2004 euc_jisx0213 koi8_r koi8_u mac_cyrillic mac_greek mac_iceland mac_latin2 mac_roman mac_turkish ptcp154 shift_jis shift_jis_2004 shift_jisx0213 cp037 cp424 cp437 cp500 cp737 cp775 cp850 cp852 cp855 cp856 cp857 cp860 cp861 cp862 cp863 cp864 cp865 cp866 cp869 cp874 cp875 cp932 cp950 cp1006 cp1026 cp1140 cp1250 cp1251 cp1252 cp1253 cp1254 cp1255 cp1256 cp1257 cp1258 |
|---|
|
|---|
|
| Character stuff |
|---|
| Named entity | not applicable |
|---|
| Alt code | not applicable |
|---|
| String stuff |
|---|
HTML/XML
numeric entities | All but a-zA-Z0-9 and space are encoded, which is a little overzealous
hexadecimal:
┍
decimal:
┍ |
|---|
| UTF8 bytestring | as hex: e2948d
(UTF8 bytestring length is 3) |
|---|
| URL-encoded UTF8 | %E2%94%8D |
|---|
Javascript
~ES3 | "\u250d" |
|---|
| ES6 | "\u{250D}" |
|---|
Python
py2 | Unicode string:
u'\u250d'
UTF8 bytestring:
'\xe2\x94\x8d' |
|---|
py3 | Unicode string:
'\u250d'
UTF8 bytestring:
b'\xe2\x94\x8d' |
|---|
| Ruby | '\u{250d}' |
|---|
| CSS (in :before/:after) | '\250D' |
|---|
TeX
(experiment) | nothing interesting to report here |
|---|
|
|---|
|
| Details |
By itself: ┍
With VS15: ┍︎
With VS16: ┍️ |
|---|
| Involved in modifier sequences | TODO |
|---|
| Involved in ZWJ sequences | TODO |
|---|
|
|---|
|
| Details | TODO |
|---|
|
|---|
|
|---|
|
|
BMP - Basic Multilingual Plane:
not allocated (48)
not allocated (16)
High Private Use Surrogates (128)
End of range that UCS2-based Unicode implementations can store.
UCS4 implementations have no real limit, UTF-16 implementations can go beyond using surrogates.
SMP - Supplemental Multilingual Plane:
not allocated (128)
not allocated (32)
not allocated (144)
not allocated (128)
not allocated (48)
not allocated (64)
not allocated (32)
not allocated (80)
not allocated (48)
not allocated (288)
not allocated (128)
not allocated (112)
not allocated (48)
not allocated (128)
not allocated (160)
not allocated (48)
not allocated (192)
not allocated (80)
not allocated (160)
not allocated (16)
not allocated (256)
not allocated (64)
not allocated (304)
not allocated (192)
not allocated (2736)
not allocated (4032)
not allocated (8576)
not allocated (96)
not allocated (688)
not allocated (96)
not allocated (64)
not allocated (9472)
not allocated (2304)
not allocated (4944)
not allocated (144)
not allocated (128)
not allocated (1360)
not allocated (208)
not allocated (368)
not allocated (1280)
not allocated (32)
not allocated (784)
not allocated (64)
not allocated (176)
not allocated (256)
not allocated (1280)
SIP - Supplemental Ideographic Plane:
not allocated (32)
not allocated (3088)
not allocated (1504)
TIP - Tertiary Ideographic Plane:
not allocated (60592)
Planes 4 through 13 - not allocated:
plane 4 (not allocated) (65536)
plane 5 (not allocated) (65536)
plane 6 (not allocated) (65536)
plane 7 (not allocated) (65536)
plane 8 (not allocated) (65536)
plane 9 (not allocated) (65536)
plane 10 (not allocated) (65536)
plane 11 (not allocated) (65536)
plane 12 (not allocated) (65536)
plane 13 (not allocated) (65536)
SSP - Supplemental Special-purpose Plane:
not allocated (128)
not allocated (65040)
PUA-A - Private Use Area A:
PUA-B - Private Use Area B:
Note that of the ~1.1 million codepoints under U+10FFFF (the current cap), only ~140K are general-purpose graphic codepoints (about half in BMP), ~130K are private use (with no defined characters), and ~830K are unused.
The grouping used above is somewhat arbitrary, but looks halfway sensible
|
|---|
|